
一直以来,我写了不少关于 AI 知识库的分享。不过,很多小伙伴在实际应用中遇到了一个痛点:满怀期待地把资料“投喂”进知识库后,却发现问答效果并不理想。这其实很正常,因为 RAG(Retrieval-Augmented Generation)并不是万能的,它也有局限性,并不适合所有场景。

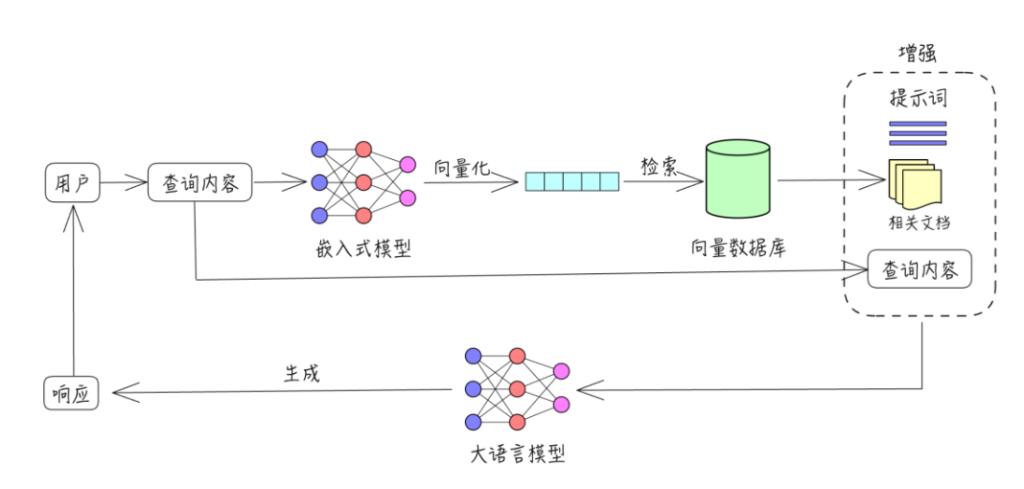
我们先来看看 RAG 的局限性:
-
文件分片导致上下文丢失:文件分片本身不是问题,但分片会导致原本连贯的内容被分割,从而导致后期检索到的内容信息不完整。
-
检索不精确:因为 RAG 是使用向量比对的方式(数学的维度)来查询语义相近的内容,但有时匹配的内容可能并不是我们真正想要的信息。
-
缺乏全局概念:由于知识库中的文件是分片存储的,每次回答只会检索部分内容,因此很难准确回答一些全局性问题(比如统计型的问题),例如“知识库中有多少位老师”“一季度有多少个订单”等。
解决方案
针对第一个问题(文件分片导致上下文丢失),我之前分享过一个解决方案:使用超长上下文模型,把相关和不相关的内容都检索出来,让大模型自己判断。感兴趣的朋友可以参考开源模型 minimax-01,支持 400 万 tokens。
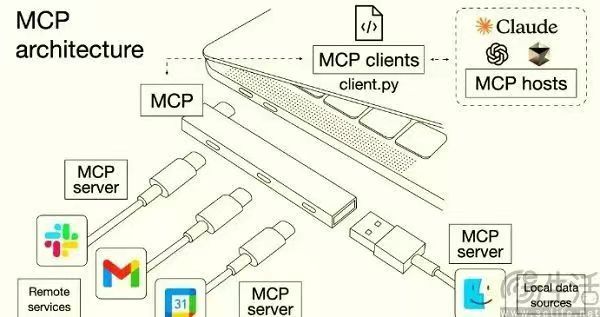
那么,剩下的两个问题(检索不精确和缺乏全局概念)该如何解决呢?其实,搭配传统数据库是一个很好的方案。虽然这个方案之前操作起来比较繁琐,但最近随着 MCP(Model-Connector Protocol)的兴起,AI 大模型接入数据库的门槛大大降低。尤其是我平时最爱用的 Trae,终于支持 MCP 了!
Trae 介绍
Trae 是一款专为中国开发者设计的 AI 编程助手,它基于人与 AI 协作开发的理念,让开发者和 AI 在恰当的时间接管工作,确保每一段代码都是人与 AI 共创的最优结果。Trae 的主要功能包括:
-
Builder 模式:从想法描述到功能实现,Trae 一气呵成,快速从 0 到 1。
-
上下文理解:Trae 能深入理解你的代码仓库,结合 IDE 内信息,准确识别需求。
-
自动补全:通过强大的上下文分析,Trae 可以实时预测和续写代码片段,大幅提升编码效率。
-
AI 协作:你可以将 AI 生成的代码一键应用到多个模块,还可以实时预览前端效果。
Trae 配置 PostgreSQL MCP
接下来,我将以 PostgreSQL 这个简单、轻量的关系型数据库为例,带大家接入 Trae 的 MCP 功能。这个方案更适合表格类型的数据,如果是文本数据,建议参考前面提到的“大力出奇迹”方案。
为什么推荐 Trae?
永久免费使用,不限功能
-
没有 Copilot 和 Cursor高昂的20刀月费 -
没有 Cursor 的“Too many free trial accounts used” -
没有 API Key 的烦恼 -
不限时、不限请求量,是真正让你用得爽的工具 -
Trae支持满血最新版DeepSeek R1 / V3,目前已经超过gpt大量模型。
中文对话一流,自然无压力
无论你是写 Vue、React,还是写 Java、Go,甚至想聊聊架构选型或者调接口技巧,Trae 都能用地道的中文跟你来回交流,还能边讲解边写代码。
你可以对它说:
-
“我这个组件能不能封装一下?” -
“帮我把这段逻辑改成 async/await” -
“这个接口怎么加缓存?用 redis 吧” 它不仅懂,还会“顺着你的思路”继续优化。
先登录注册【直接搜索即可】
邀请好友还可以获取积分,兑换奖品【我就不赚这个奖励了,你们自己搜索吧】
1. 安装 PostgreSQL【教程自行搜索即可,安装简单方便】
访问 PostgreSQL 官网下载地址:PostgreSQL 官网,选择适合你操作系统的版本进行下载和安装。
2. 安装图形化界面工具
为了方便操作数据库,我们可以安装一个图形化界面工具,比如 DBeaver。访问 DBeaver 官网:DBeaver 下载,选择适合你操作系统的版本进行下载和安装。
安装完成后,打开 DBeaver,点击右上角的小 + 号,选中 PostgreSQL 添加数据库。按照提示填写配置信息,包括用户名、密码等。连接成功后,你会看到数据库图标上有一个小勾。
3. 配置 Trae 的 MCP
打开 Trae,按照提示添加 MCP。如果第一次没有 MCP,会提示需要添加。进入 MCP 市场,添加 PostgreSQL。
特别注意:复制的 PostgreSQL URL 不能直接粘贴使用,需要参考 Trae 给出的格式进行调整。例如:
postgresql://postgres:密码@127.0.0.1:5432/postgres
将其中的“密码”替换为你自己的 PostgreSQL 密码。
如果在配置过程中遇到任何问题,可以随时让 Trae 的 AI 帮你解决。
4. 测试 PostgreSQL MCP 效果
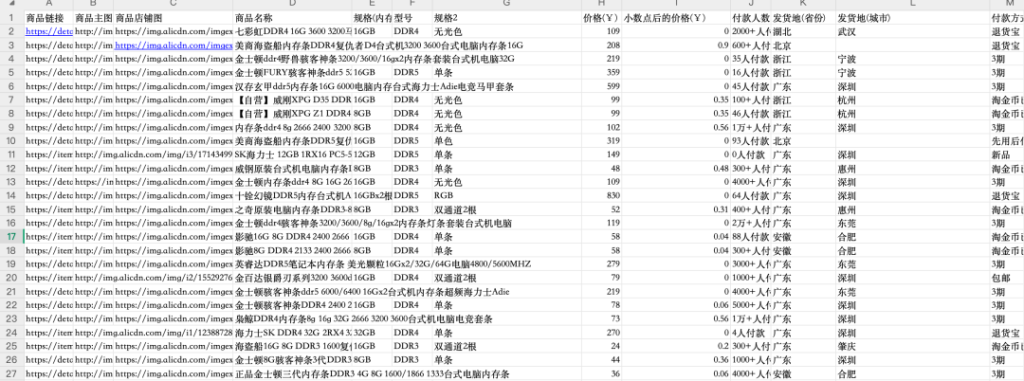
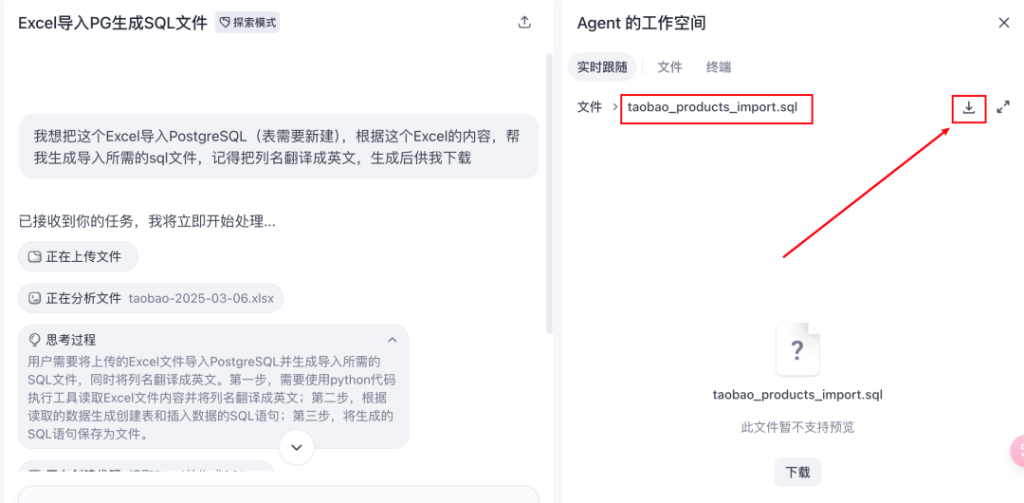
为了测试效果,我们需要准备一些测试数据。我准备了一个 Excel 表格,包含一些内存条商品信息。我们可以使用「扣子空间」将这个 Excel 表格转换为可直接导入 PostgreSQL 的 SQL 文件。
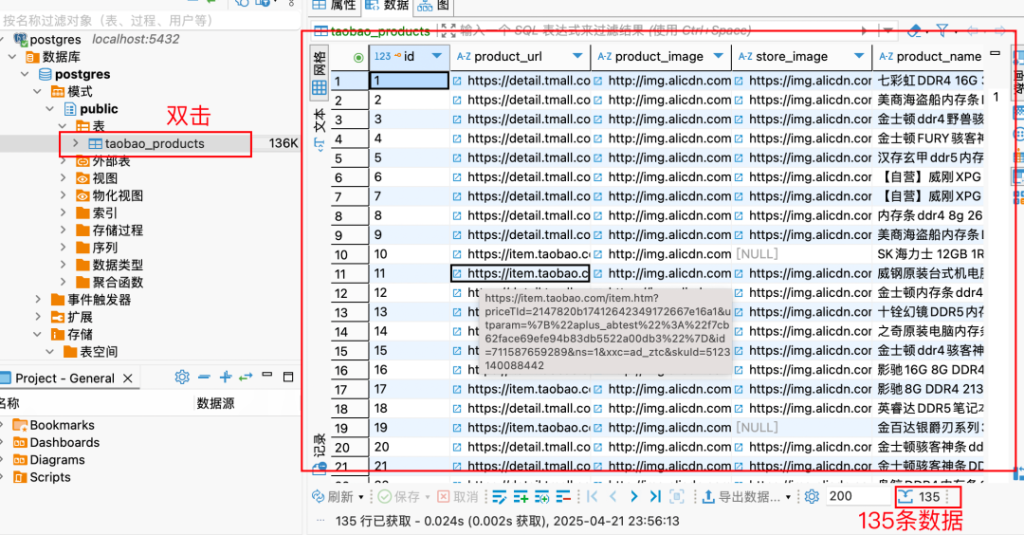
在 Trae 中,将生成的 SQL 文件导入 PostgreSQL 数据库。导入成功后,我们可以在 Trae 中测试查询效果。
结合 RAG 和数据库
这个方案还可以结合 RAG 一起使用。例如,可以设计一个工作流:当用户的问题是全局性或统计性质的,就走数据库;否则就走 RAG。这样可以大大提升整个知识库的检索精度。
© 版权声明
THE END


![[破解]cursor 注册码共享使用方法-首码网赚项目网](https://zibovip.cn/wp-content/uploads/2025/04/image-8.png)



暂无评论内容